问题一、客户真正的问题,不是“没有 AI”,而是“知识根本没管起来”
我先花了几天把他们内部现状摸了一遍。
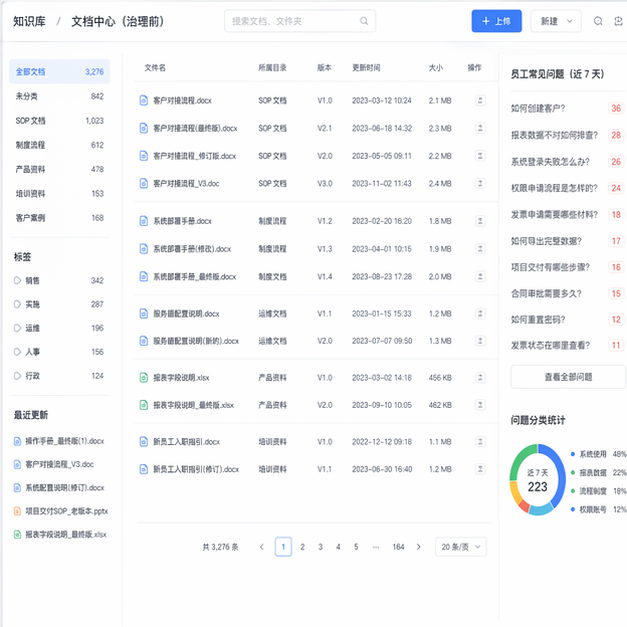
文件分布非常典型:
- 产品资料在共享盘里,版本很多,命名混乱;
- 培训 PPT 有,但很多已经过期;
- 售后常见问题有 Word 文档,也有 Excel 表,格式完全不统一;
- 一线同事最常用的“经验”,其实大量沉在企业微信聊天记录里;
- 不同部门对同一个问题,口径还不完全一致。
比如一个很普通的问题:“客户问这个功能能不能支持某种特殊流程?”
销售说可以,因为他记得有个老项目做过类似定制;
交付说要看版本,因为不是所有客户都在同一套配置上;
售后说别先答应,因为后面牵扯权限和接口限制;
项目经理说等一下,我翻翻上次那个项目的群记录。
你看,这不是谁不负责,而是信息根本没有被收口。
所以我没有一上来就聊模型参数、向量数据库、RAG 架构这些词。我先做的是一件很土,但很关键的事:把知识源头捋清楚。
我把他们内部资料先按用途拆成了几层:
第一层是“标准知识”,比如产品说明、交付文档、标准操作手册、培训材料,这些东西理论上应该最稳定;
第二层是“经验知识”,比如常见问题、实施避坑、售后处理套路、客户异议怎么回,这些东西价值很高,但原来最散;
第三层是“敏感知识”,比如报价逻辑、合同条款、特定客户项目细节、内部权限规则,这类内容不能谁都能看。
很多公司做知识库失败,就是因为把所有文件一股脑塞进去,最后问出来的答案看似像那么回事,实际上要么答得太空,要么把不该说的也说出来了。
这类系统一旦碰到内部权限问题,死得比谁都快。
梳理二、我没先做“聊天界面”,而是先做了文档清洗和版本治理
老板通常更容易被一个会聊天的界面打动,但我这次没有先做前台,而是先从后台的“脏活”下手。
第一步,是清理旧资料。
这个活一点都不性感,但特别重要。因为企业里大量文档,不是不能用,而是“半能用”。标题像人话,正文是旧版本;文件名看着是最新版,里面的截图还是两年前的;FAQ 看起来很完整,但某些答案早就不适用了。
如果这些东西不先处理,AI 只会一本正经地把过期信息说得更像真理。
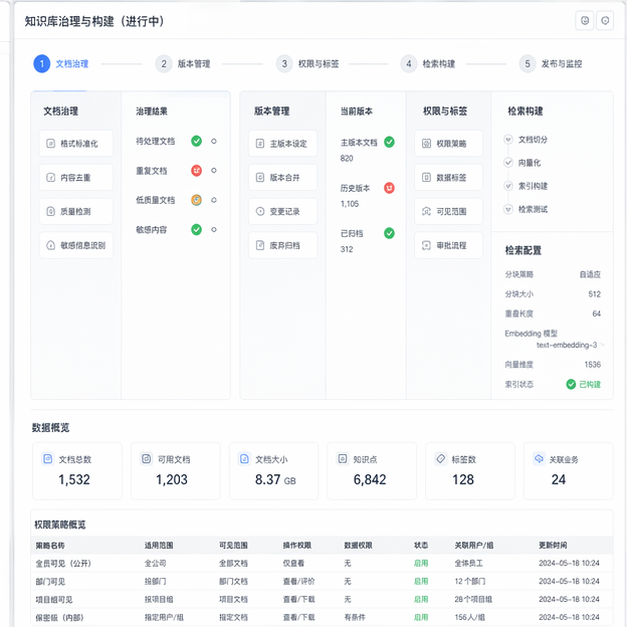
所以我先帮他们做了三件事:
- 去掉明显过期、重复、冲突的文档;
- 给保留资料补标签,比如部门、业务线、适用版本、更新时间、是否敏感;
- 把原来“大而全”的文档,拆成更适合检索的小知识片段。
这里很多人会误会,以为 AI 知识库就是把 PDF 上传进去就行。实际不是。
真正能落地的知识库,一定要把“文件”处理成“可检索、可追溯、可标记权限”的知识单元。否则你问一个具体问题,大模型拿到的是几十页大而泛的上下文,它不但答不准,还特别容易把相近概念混在一起。
所以我在这个项目里,没有走那种“一切都靠模型临场发挥”的路线,而是把文档清洗、切片、标注这层做得比较细。说白了,就是先把资料整理成机器能用、也方便人回溯的样子。
这一步做完以后,很多客户自己都挺意外的。因为他们原本以为 AI 项目的核心工作量都在“调模型”,结果真正花精力的,反而是内部知识治理。
这也很正常。企业里的问题,十有八九不是技术太新,而是基础太乱。
方案三、技术上,重点不在模型名字,而在检索、权限和回溯
这点我得单独说一句。
很多人一聊 AI 知识库,就先盯着“模型够不够聪明”。但我这次真正关心的,不是首页挂哪个名字,而是这几个问题:
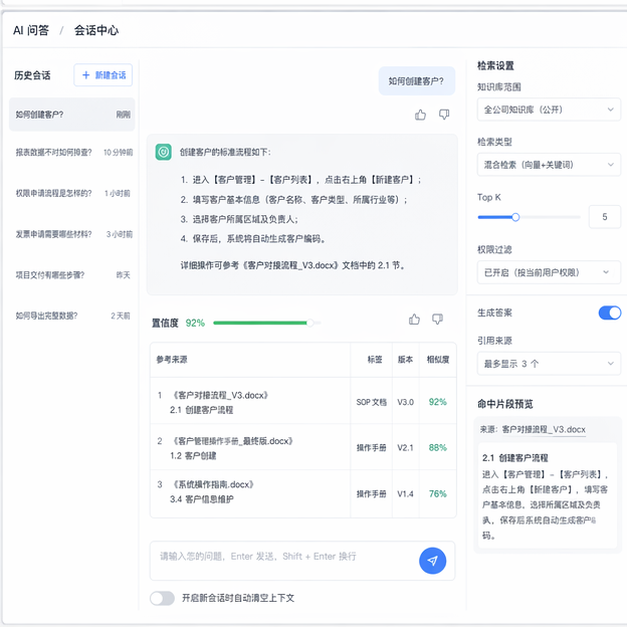
- 能不能查到对的资料;
- 回答时能不能带出处;
- 不同部门看到的内容是不是隔离的;
- 旧版本会不会误伤新版本;
- 出错以后,运营的人能不能知道错在哪。
如果这些事情做不好,前台聊天再丝滑,落到企业内部也是个隐患。
所以我最后定的技术路线,不是“把所有文件丢进去,然后指望模型自己悟”,而是把系统拆开来做:
文档解析 + 分层切片 + 元数据标注 + 混合检索 + 重排 + 大模型生成 + 引用回溯 + 人工反馈闭环。
翻成人话就是:先尽量把该找的内容找准,再让模型把话说顺。
这里面最关键的,其实是中间那几层。
因为企业文档不是互联网文章,它有很多版本差异、部门口径和权限边界。你把这些东西不加处理地一股脑扔进去,系统大概率也会“一本正经地答错”。但如果先把文档拆开、标好标签、把检索和权限控制做好,再让问答层去组织语言,结果就会稳很多。
我这次也是按这个思路做的:回答层和检索层分开,资料按业务线和敏感级别管理,高风险问题保留回溯链路,不让系统凭感觉乱答。这样后面不管是调提示词、换模型,还是补资料、修规则,都不会把整套东西推倒重来。
说白了,这类系统真正值钱的,不是谁家的模型名写在宣传页上,而是它能不能在企业内部长期跑得稳、出问题能回看、规则变化能跟得上。
落地四、这个项目最难的,不是问答,而是“别胡说”
很多没做过企业场景的人,会把 AI 知识库理解成一个更聪明的搜索框。
其实不是。
企业最怕的,不是 AI 回答得慢,而是 AI 说得太像真的。
比如客户内部有很多“历史上特殊处理过的案例”。这些内容如果不打标,模型就很容易把个例说成通例。再比如有些报价规则是部门可见,有些合同条款只有管理层能看;如果检索层不做权限切分,前台答得再丝滑,也是在埋雷。
所以我在这个项目里,把“不要胡说”这件事放在了很前面。
具体做法不是去追求一个永不出错的模型,而是尽量让系统在答题前先缩小犯错空间:
- 问答前先做检索,不让模型凭空发挥;
- 检索结果不足时,宁可提示“当前资料不足”,也不硬编;
- 回答里保留引用来源,方便用户回点原文;
- 高风险问题不给自由发挥,直接走固定回答模板或人工升级;
- 用户可以对答案做“有用/无用”反馈,后面持续修。
企业场景和普通 AI 聊天最大差别就在这。普通用户愿意接受一点“像人但偶尔不准”的回答,企业不行。企业要的是:出了问题,至少能追溯;答错了,知道错在哪;修完以后,下次别再错。
这一点不解决,知识库越聪明,风险越大。
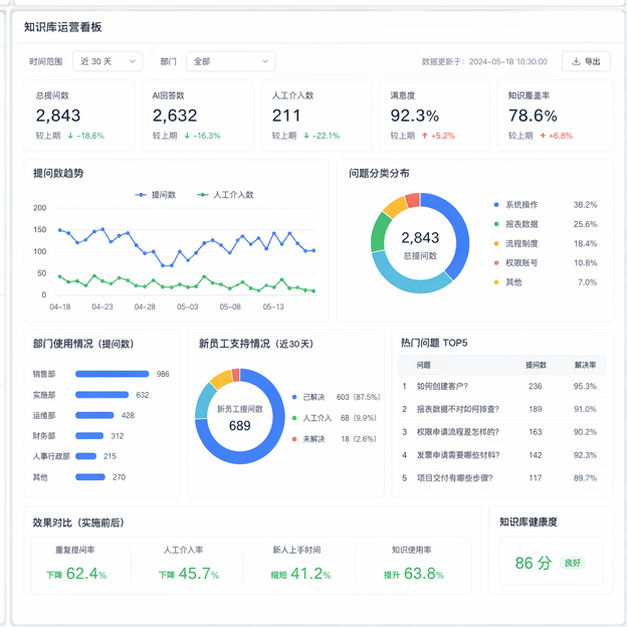
成果五、落地之后,客户最满意的不是“AI 很聪明”,而是终于没人来回问同一件事了
项目上线一段时间后,客户给我的反馈很有意思。
他们夸得最多的,不是“这个系统回答像真人”,而是另外几件很实际的事:
第一,新人终于有地方先自己查了。
以前新人碰到问题,最省事的办法就是问人。现在至少第一步不是“张口就问”,而是先去知识库里搜。哪怕最后还需要请教同事,前面那层重复性问题已经被挡掉不少了。
第二,老员工被打断的频率明显少了。
这一点很多老板平时不一定看得见,但现场做事的人感受特别明显。原来一天里最碎的时间,全花在重复解释上了。系统上线后,那些标准问题终于有了一个统一出口,老员工可以把精力留给真正复杂的情况。
第三,跨部门口径开始慢慢统一。
这也是我比较看重的一点。很多公司不是没人干活,而是同一件事每个部门说法都不一样。知识库真正的价值,不只是“回答问题”,而是帮公司把原本模糊的规则、经验、边界,逐渐变成更一致的共识。
第四,老板第一次能看见“哪些问题总在被问”。
这个特别关键。因为一旦问题被系统记录下来,老板看到的就不只是“大家工作挺忙”,而是会知道:到底是哪个环节资料不清楚,哪个流程设计得别扭,哪个部门交接有断层。换句话说,AI 知识库不只是一个回答工具,它也是一个组织问题的观察窗口。
复盘六、这类项目值不值得做,关键不在 AI,而在组织有没有沉淀经验的意愿
我后来跟客户复盘时说了一句挺直白的话:
“你们这次做的,不是一个 AI 小玩具,而是在补公司过去几年一直没补上的知识基础设施。”
很多企业老板一听“知识库”,会觉得这事偏虚,没那么急。可一旦公司开始扩人、分部门、做项目交付、做售后、做跨团队协作,这件事迟早要补。
以前没有 AI,这个问题也存在,只是大家忍着。
现在 AI 把这个问题放大了。因为一旦你想让系统参与回答、培训、辅助决策,你就会发现:公司内部到底有没有一套可以被机器调用、也能被人验证的知识体系。
如果没有,那就别急着谈什么智能化升级。
所以我一直觉得,企业做 AI 知识库,真正值钱的不是“接了个大模型”,而是借这个机会把知识重新整理了一遍,把经验从“人脑私有”变成“组织可复用”,把原来谁都说不清的东西,慢慢沉淀成可查、可管、可回溯的资产。
说到底,这不是一个炫技项目。
它更像一次组织修补。
心声老T心声
很多企业在 AI 这件事上最容易走偏的地方,就是一上来先问:能不能做个像 ChatGPT 那样的东西?
我现在通常会反问一句:你们内部那些该给 AI 用的资料,自己人找起来都顺不顺?
如果这个问题的答案是否定的,那先别急着上花哨界面。先把知识源、版本、权限、口径这几件事收一收,后面的 AI 才有意义。
真正能落地的 AI 项目,往往没那么“炫”,但很实用。表面上看,你只是多了一个会回答问题的系统;实际上,你是在把企业最容易流失的那部分经验,重新拽回到公司自己手里。
这事不热闹,但值钱。

